
- Как устроен штрихкод?
- Введение
- Получаем битовую последовательность
- Декодирование
- Заключение
- Generate Free Barcodes Online
- Your Benefit
- This Barcode Generator is Free
- Бесплатно Создать Штрихкоды Онлайн
- Данный генератор штрихкодов является бесплатным
- Code-128, GS1-128 Barcode Symbology
- Classification
- History
- Symbol Structure
- Technical Data
- Sub Variants, Derivatives
- Какие символы кодируются в штрих-код CODE-128?
- Внешний вид штрих-кода CODE-128
- Структура Code 128
- Контрольный знак Code 128
- Малоизвестные факты о штрихкодах — загадочные цифры под штрихкодом
- Кассовый штрихкод
- GS1 DataMatrix
Как устроен штрихкод?
Время на прочтение
7 мин
Со штрихкодами современный человек сталкивается каждый день, даже не задумываясь об этом. Когда мы покупаем в супермаркете продукты, их коды считываются именно с помощью штрихкода. Также посылки, товары на складах, и прочее и прочее. Однако, мало кто знает, как же реально это работает.
Как устроен баркод, и что закодировано на этой картинке?

Попробуем разобраться, заодно напишем декодер таких кодов.
Введение
Использование штрихкодов имеет давнюю историю. Первые попытки автоматизации начинались еще в 50х, патент на устройство считывания кодов был получен в 1952г. Инженер, занимавшийся сортировкой вагонов на железной дороге, захотел упростить процесс. Идея была очевидной — кодировать номер с помощью полос и считывать их с помощью фотоэлементов. В 1962г коды стали официально использоваться для идентификации вагонов на американской железной дороге (система KarTrak), в 1968 прожектор заменили лазерным лучом, что позволило повысить точность и уменьшить размер считывателя. В 1973г появился формат «универсального кода продукта» (Universal Product Code), и в 1974 с использованием сканера кодов был продан первый продукт (жевательная резинка Wrigley’s — это же США;) в супермаркете. В 1984 треть магазинов использовали штриходы, в России же они начали использоваться примерно с 90х годов.
Разных кодов под разные задачи сейчас используется довольно много, к примеру, последовательность «12345678» может быть представлена такими способами (и это еще не все):

Приступим к побитовому разбору. Далее, все ниженаписанное будет относиться к виду «Code-128» — просто потому, что его формат довольно простой и понятный. Желающие поэкспериментировать с другими видами, могут открыть онлайн-генератор и посмотреть самостоятельно.
На первый взгляд штрихкод кажется просто беспорядочной последовательностью линий, на самом деле, его структура четко фиксирована:

1 — Пустое место, нужное для четкого определения начала кода
2 — Стартовый символ. Для Code-128 возможны 3 варианта (называемых А, В и С): 11010000100, 11010010000 или 11010011100, им соответствуют разные кодовые таблицы (подробнее в Википедии).
3 — Собственно код, содержащий нужные нам данные
4 — Контрольная сумма
5 — Стоп символ. Для Code-128 это 1100011101011.
6(1) — Пустое место.
Теперь о том, как кодируются биты. Тут все очень просто — если взять ширину самой тонкой линии за «1», то линия двойной ширины даст код «11», тройная «111», и так далее. Пустое место будет «0» или «00» или «000» по тому же самому принципу. Желающие могут сравнить стартовый код на картинке, чтобы убедиться что правило выполняется.
Теперь можно начинать программировать.
Получаем битовую последовательность
В принципе, это самая сложная часть, и разумеется, алгоритмически ее можно реализовать по-разному. Не уверен, что приведенный ниже алгоритм оптимальный, но для учебного примера его вполне достаточно.
Для начала загрузим изображение, растянем его по ширине, возьмем из середины изображения горизонтальную линию, преобразуем ее в ч/б и загрузим в виде массива.
На штрихкоде черному соответствует «1», а в RGB наоборот, 0, так что массив нужно инвертировать. Заодно вычислим среднее значение.
hor_data = 255 — hor_data
avg = np.average(hor_data)
plt.plot(hor_data)
plt.show()
Запускаем программу, чтобы убедиться, что баркод загружен корректно:
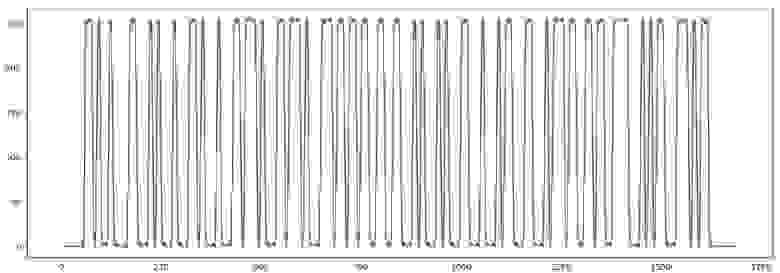
Теперь нужно определить ширину одного «бита». Для этого мы выделим начало стартовой последовательности «1101», записывая моменты перехода графика через среднюю линию.
Мы записываем только переходы через середину, так что код «1101» будет записан как «101», но нам этого достаточно чтобы узнать его ширину в пикселах.
Теперь собственно декодирование. Находим очередной переход через середину, и определяем число бит, попавших в интервал. Поскольку совпадение не абсолютное (код может быть слегка изогнут или растянут), используем округление.
Не уверен что это оптимальный вариант, возможно, есть способ лучше, желающие могут написать в комментариях.
Если все было сделано правильно, то мы получаем на выходе примерно такую последовательность:
Декодирование
Здесь никаких сложностей в принципе, нет. Символы в Code-128 кодируются 11-битным кодом, который имеет 3 разновидности (А, В и С) и может хранить либо разные кодировки символов, либо цифры от 00 до 99.
В нашем случае, начало последовательности 11010010000, что соответствует «Code B». Было жутко влом вбивать вручную все коды из Википедии, поэтому таблица была просто скопирована из браузера и ее парсинг был тоже сделан на Python (hint: на продакшене так делать не надо).
Теперь осталось самое простое. Разбиваем нашу битовую последовательность на 11-символьные блоки:
Наконец, формируем строку и выводим ее на экран:
Ответ на то, что закодировано в таблице, приводить не буду, пусть это будет домашним заданием для читателей (использование готовых программ для смартфонов будет считаться читерством:).
В коде также не реализована проверка CRC, желающие могут сделать это самостоятельно.
Разумеется, алгоритм неидеален, и был написан за полчаса. Для более профессиональных целей есть готовые библиотеки, например pyzbar. Код с использованием такой библиотеки займет всего 4 строчки:
from pyzbar.pyzbar import decode
img = Image.open(image_path)
decode = decode(img)
print(decode)
(предварительно нужно установить библиотеку, введя команду «pip install pyzbar»)
Дополнение: о подсчете CRC написал в комментариях пользователь vinograd19:
Интересна история контрольной цифры. Она возникла эволюционно.
Контрольная цифра нужна для того, чтобы избежать неправильного декодирования. Если штрихкод был 1234, а его распознали как 7234, то нужна валидация, которая предупредит замену 1 на 7. Валидация может быть неточная, чтобы хотя бы в 90% невалидные номера определялись заранее.
1-й подход: Давайте просто возьмем сумму. Чтобы в остатке от деления на 10 был 0. Ну то есть первые 12 символов несут информационную нагрузку, а последняя цифры подбирается так, чтобы сумма цифр делилась на 10. Декодируем последовательность, если сумма не делится на десять — значит декодировали с багом и нужно сделать это еще раз. Например, код 1234 — валидный. 1+2+3+4 = 10. Код 1216 — тоже валидный, а вот 1218 — нет.
Это позволяет избежать проблем с автоматикой. Однако в момент создания штрихкодов был фоллбек в виде набивания номер на клавишах. И там есть плохой кейс: если поменять порядок следования двух цифр, то контрольная сумма не меняется, и это плохо. То есть если штрихкод 1234 был вбит как 2134, контрольная сумма сойдется, а вот номер мы вбили неправильный. Оказывается, неправильный порядок цифр — это распространенный кейс, если стучать по клавишам быстро.
2-й подход. Хорошо, давайте сумму сделаем чуть сложнее. Чтобы цифры на четных местах учитывались дважды. Тогда при изменении порядка, сумма точно не сойдется к нужной. Например код 2364 валидный (2 + 3+3 + 6 + 4+4 = 20), а код 3264 — невалидный (3+ 2+2 + 6 + 4+4 = 19). Но тут оказался еще один плохой пример вбития. Некоторые клавиатуры такие, что десять цифр располагаются в два ряда. первый ряд 12345 и под ним второй второй ряд 67890. Если вместо клавишы «1» нажать правее клавишу «2», то контрольная сумма предупредит неправильный ввод. А вот если вместо клавишу «1» нажать ниже клавишу «6» — то может не предупредить. Ведь 6=1+5, и в случае когда эта цифра стоит на четном месте при вычислении контрольной суммы, мы имеем 2*6 = 2*1 + 2*5. То есть контрольная сумму увеличилась ровно на 10, поэтому ее последняя цифра не изменилась. Например контрольные суммы кодв 2134 и 2634 одинаковые. Та же ошибка будет, если мы вместо 2 нажмем 7, вместо 3 нажмем 8 и тд.
Описанный способ стал стандартом вычисления контрольной суммы EAN13 за небольшими правками: число цифр стало фиксированным и равно 13, где 13-ая — это та самая контрольная цифра. Цифры на нечетных местах считаются трижды, на четных — один раз.
Заключение
Как можно видеть, даже такая простая вещь как штрихкод, имеет в себе немало интересного. Кстати, еще один лайфхак для тех, кто дочитал до сюда — текст под штрихкодом (если он есть) полностью дублирует его содержание. Это сделано для того, чтобы в случае нечитабельности кода, оператор мог ввести его вручную. Так что узнать содержимое штрихкода обычно просто — достаточно посмотреть на текст под ним.
Как подсказали в комментариях, наиболее популярным в торговле является код EAN-13, битовое кодирование там такое же, а структуру символов желающие могут посмотреть самостоятельно.
Если у читателей не пропал интерес, отдельно можно рассмотреть QR-коды.
Спасибо за внимание.
Однажды в процессе производственной деятельности у меня появилась необходимость генерации штрихкода по стандарту code128. Появилась в виду того, что имевшаяся в эксплуатации функция (хранимая процедура в базе Oracle) генерировала клёвый, полосатый штрихкод, который читался не во всех случаях. Разработчики в своё время оттестировали эту процедуру весьма некачественно, но перерабатывать уже не собирались т.к. проект был давно сдан, а потребности в считывании так и не появились.
Самое время пощупать теорию. Вернее мы с ней познакомились намного раньше, просто до последнего не хотелось ввязываться в дополнительное программирование. Исторические факты опустим, а вот очень хорошее техническое описание имеется на http://code128.narod.ru/ (в архиве это файл Descript.doc ) либо в Википедии. В принципе, это всё что нам потребуется для понимания и собственной реализации алгоритма (тут я немного лукавлю — из любой готовой библиотеки нужно выдрать таблицы толщин штрихов, чтобы не вбивать их вручную). Ну и напишем всё это безобразие на php, заодно посмотрим пару прикольных моментов, про которые все забывают или стесняются использовать.
Теория гласит, что code128 позволяет закодировать (сюрпрайз!) 128 символов, при этом нам доступно 3 алфавита, между которыми можно переключаться по ходу дела. Наибольший практический интерес представляют алфавит «B» для буквенно-цифровых символов и алфавит «С» который используется для кодирования цифр, но с некоторой оптимизацией — одним штриховым символом можно закодировать 2 исходных символа и получить более короткий штрихкод. Вот эта оптимизация пока не даётся ни одному php-разработчику — максимум что я видел это попытка в начале кодирования определить состав строки и при наличии только цифр переключаться на алфавит «С». В остальных библиотеках это банальная подстановка символов штрихкода по таблице.
Для начала осмотрим приборы и материалы — в начале строки можем задать алфавит для кодирования, перед каждым символом можем переключить алфавит. Также мы на входе ограничены по длине строки — это очень хорошо и важно для нас. Имеем цель — получить штрихкод. Точнее, самый короткий штрихкод.
Разберём пару примеров. Допустим у нас есть последовательность «ABC12DE» попробуем её закодировать разными методами, на примере изображены слева только алфавит B, справа — совместно B и С:
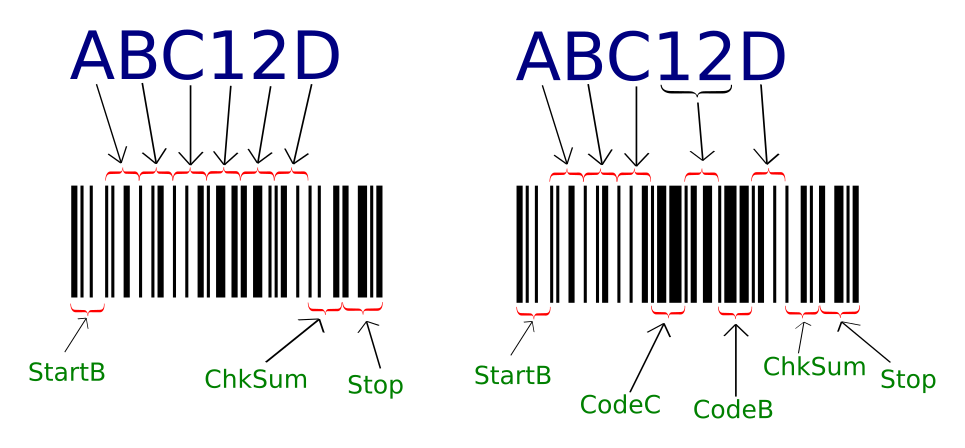
Наша попытка оптимизировать длину кода используя более короткий алфавит потерпела фиаско — мы получили дополнительные символы на переключениях алфавита и в результате штрихкод стал на 1 символ длиннее. Если хорошо подумать, то переключение на алфавит С выгодно при наличии 6 и более цифр подряд. Но есть ведь и граничные случаи — цифры в конце последовательности, в начале, а есть еще вариант с нечетным количеством цифр и тогда надо пристально смотреть когда переключаться на алфавит С — с первой цифры или со второй? В общем вариантов достаточно много, что в итоге у большинства отбивает желание оптимизировать длину кода, а делать всё одним алфавитом.
И вот тут нас озаряет, что работа с рекурсивной функцией избавит нас от рассмотрения всех этих условий и задача станет невероятно простой — функция будет вызывать сама себя с тремя вариантами кодирования текущего символа и возвращать наиболее короткий (итоговый) вариант. Причём длина варианта включает в себя и символ переключения между алфавитами. Причин отказа от захода в ветку алгоритма совсем немного — либо кончился входной поток, либо мы не можем закодировать символ(ы) данным алфавитом (например нет 2-х цифр для алфавита «С»). Так, как входной поток имеет ограничение по длине, то дерево не будет расти бесконечно! По тексту будем реализовывать только алфавит «B» и «C» — проще для понимания и потом объясню остальное 🙂
Сразу набросаем простейший класс который содержит сам текст, такие-же классы для рассмотрения вариантов по алфавиту B и С, длину последовательности. Делаем ему минимальный конструктор — на входе строка для кодирования, режим кодирования, ссылки на потомков. В начале конструктора добавляем проверки, чтобы не прорабатывать данную ветку дерева:
и сразу ловим конкретный косяк — куча «пустых» объектов. И это не смотря на то что мы явно отказались создаваться и вроде как железно возвращаем NULL! В общем сразу надо понять, что в php объект создаётся в любом случае. Полагаю что также и в остальных объектно-ориентированных языках. И все эти условия надо проверять перед созданием объекта. Следовательно правильный конструктор будет выглядеть примерно так:
Не считая того, что мы избавились от пустых объектов, код получился даже немного короче чем прототип. Дальше начнём немного оптимизировать — добавим небольшой трюк: вместо того чтобы делать кучу проверок является ли последовательность символами, цифрами, их количество и т.д. просто смотрим в таблице наличие такого индекса в алфавите. Я уже писал что таблицу можно добыть в любой библиотеке реализующей кодирование code128? В общем напоминаю ещё раз, и готовый кусочек кода, который мне уже нравится, приведен ниже:
Дерево строится, но результата пока не видно. Следующим этапом необходимо определить самую короткую ветку: Первый вариант — заводим в классе счётчик и увеличиваем его при каждом переходе на ветку. Как только достигнем дна (конца исходного текста), на концах дерева будет указан размер финального кода. Второй вариант — конечные веточки ставят себе размер 1, а дальше родитель решает какой из потомков имеет код короче и ставит себе размер на 1 или 2 больше. Почему на 2? Надо учитывать накладные расходы на переключение алфавита. Кстати и в первом варианте это тоже надо учитывать. В итоге в корне дерева будет длина самой короткой последовательности. Чем хорош первый вариант? Получение итоговой последовательности практически мгновенное — возвращаешься «по папе» к корню дерева. Ну и недостаток — чтобы найти самую короткую ветку надо сделать полный обход дерева. Второй вариант — длина самой короткой последовательности известна и находится в одном месте, но получение последовательности чуток посложнее, хотя и не требует полного обхода. Попробуем проработать первый вариант — доделать надо совсем немного, просто родитель после создания потомков должен выбрать самого короткого потомка и сохранить ссылку на конечный элемент ветки. Выразился невероятно коряво, но Вы посмотрите код — там ещё страшнее 🙂
Итак, худо-бедно мы нашли самый короткий путь (штрихкод). Надо его вывести для начала на экран. Делаем в два этапа: сначала от потомка возвращаемся к родителю. Итоговые символы, включая переключение между алфавитами, пушим (push) в массив. Да, в PHP есть такая функция, и она позволяет нам сделать из массива довольно удобный стэк.
Когда потребуется вывести строку — используем array_pop. Таким образом, мы по прежнему используем данный массив как стэк и легко выводим информацию в обратном порядке. Попутно готовим дополнительную обвязку для нашего штрихкода — старт/стоп/контрольная сумма.
Финал совсем близко — я уже устал писать, Вы устали читать. Предлагаю пробежаться весьма бегло. Само рисование сделано в виде SVG. Для данной задачи весьма удобно — нет необходимости кодировать размеры изображения, они будут задаваться тэгами на страничке. Кроме того, рендеринг и масштабирование осуществляется конечным устройством, что обеспечит необходимое качество в dpi соответствующее устройству вывода.
Появился глобальный массив $barPattern. Искать в файле tables.php рядом с $symCode. Кусочек приведу. Там всё просто — для заданного кода выходного символа чередуются толщины черных и белых штрихов:
$barPattern = array(
‘212222’, /* 0 */
‘222122’, /* 1 */
‘222221’, /* 2 */
‘121223’, /* 3 */
‘121322’, /* 4 */
Как этим пользоваться? В файл с классом в конец добавим пару строк:
попробовать можно сразу, вставив в html-страничку примерно вот такой тэг:
Ну и напоследок. Реализованы только алфавиты «B» и «С». Уложился примерно в 100 строчек, не считая таблиц перекодировки. Реализовать алфавит «А» можно аналогичным способом просто дописав конструктор и таблицу с алфавитами, только желательно учесть один хитрый код, позволяющий кратковременно переключиться на один символ другого алфавита. Самому дописать у меня нет ни желания, ни времени, ни прочих мотиваций. (Полу)готовый проект вероятно пополнит кладбище штрихкодировщиков на гитхабе — если у кого есть желание продолжить проект — пишите, не стесняйтесь.
Generate Free Barcodes Online
Linear Barcodes, 2D Codes, GS1 DataBar, Postal Barcodes and many more!
This online barcode generator demonstrates the capabilities of the
TBarCode SDK
barcode components.
TBarCode simplifies bar code creation in your application — e.g. in C# .NET, VB .NET, Microsoft® ASP.NET, ASP, PHP, Delphi and other programming languages.
Test this online barcode-generator without any software installation
(Terms of Service) and generate your barcodes right now:
EAN,
UPC,
GS1 DataBar,
Code-128,
QR Code®,
Data Matrix,
PDF417,
Postal Codes,
ISBN, etc.
Your Benefit
We’ll be adding new features exclusively for our members.
This Barcode Generator is Free
You may use this barcode generator as part of your non-commercial web-application or web-site to create barcodes, QR codes and other 2D codes with your own data.
In return, we ask you to implement a back-link with the text
«TEC-IT Barcode Generator» on your web-site.
Back-linking to www.tec-it.com is highly appreciated,
the use of TEC-IT logos is optional.
For back-linking refer to the prepared HTML-code, set your barcode data in the GET parameter «data».
Terms of Service:
This application as well as the generated output are intended solely for non-commercial and/or private use.
The use is permitted only for legal purposes and according to the valid national or international regulations.
The functionality and/or uninterrupted availability of this free service can’t be guaranteed.
Commercial use is only permitted after approval by TEC-IT in writing.
General Terms of Use and Privacy Policy.
Version: 3.7.2.13177
Бесплатно Создать Штрихкоды Онлайн
Линейные Штрихкоды, 2D Коды, GS1 DataBar, Почтовые Штрихкоды и многие другие!
Данный онлайн генератор штрихкодов демонстрирует возможности
программных компонентов
приложения TBarCode SDK.
TBarCode
упрощает создание штрихкодов в Ваших приложениях, например в C# .NET, VB .NET, Microsoft® ASP.NET, ASP, PHP, Delphi и многих других языках программирования.
Вы можете протестировать этот онлайн генератор штрихкодов без установки дополнительного программного обеспечения
(Условия Предоставления Услуг).
На данной странице Вы можете сгенерировать такие штрихкоды, как
EAN,
UPC,
GS1 DataBar,
Code-128,
QR Code®,
Data Matrix,
PDF417,
Почтовые Штрихкоды,
ISBN и многие другие.
Для зарегистрированных пользователей в ближайшее время будут добавлены новые расширенные функции.
Спасибо за Ваш интерес! Для получения дополнительной информации, пожалуйста, свяжитесь с нами!
Данный генератор штрихкодов является бесплатным
Вы можете использовать данный генератор штрих-кодов как часть Вашего некоммерческого веб-приложения или веб-сайта для создания штрих-кодов, QR-кодов и других 2D-кодов с собственными данными.
В ответ мы просим Вас разместить на Вашем сайте обратную ссылку с текстом «Генератор штрихкодов от TEC-IT».
Использование логотипов TEC-IT опционально.
Пожалуйста, свяжитесь с нами, если Вы хотите использовать данный сервис в коммерческих целях.
Для размещения обратной ссылки используйте подготовленный HTML-код.
Условия Предоставления Услуг:
Это приложение, а также результаты полученные с ее помощью предназначены исключительно для некоммерческого и/или частного использования.
Использование разрешено только для законных целей, в соответствии с национальным или международным законодательством.
Функционирование и/или непрерывная доступность этого бесплатного сервиса не может быть гарантированна.
Коммерческое использование возможно только после письменного согласования с компанией TEC-IT.
Общие условия использования и Политика конфиденциальности.
Версия: 3.7.2.13177
Code-128, GS1-128 Barcode Symbology
Due to the high data density, Code 128 is used in many areas:
Classification
Code 128 is a modern and neutral linear barcode type with high data density. It is widely used in industry and commerce because of its dynamic and complex design, which can represent both alphabetic and numeric characters without compromising the density of the barcode. Code 128 generally results in more compact barcodes compared to other methods such as Code 39, especially when the texts contain mostly digits.
History
Code 128 was developed in 1981 by the US Computer Identics Corporation for the automatic identification of data. The name 128 means that all 128 ASCII characters can be encoded. Ted Williams is credited with the invention.
After creation of Code 128, the code was adopted by EAN/UCC (now GS1) under the name EAN-128/UCC-128 (now GS1-128). Such barcodes include FNC1 characters, application identifiers and parentheses in the human-readable interpretation characters (see details below).
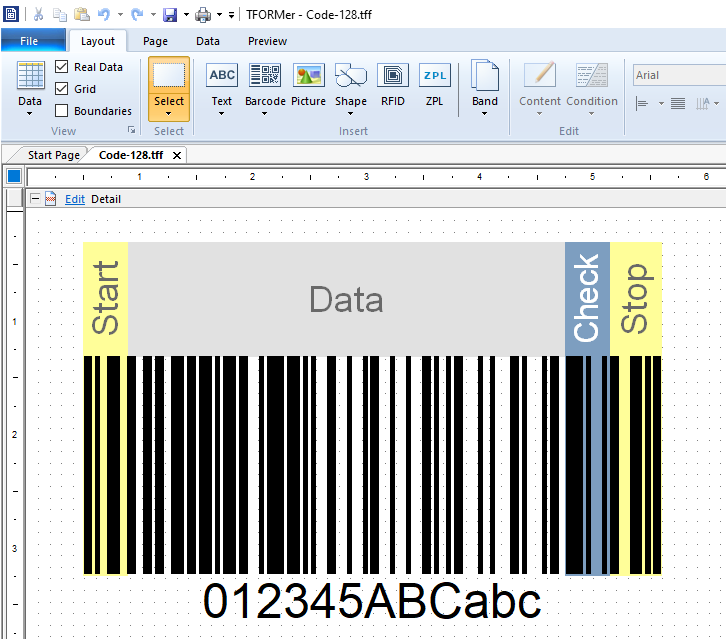
Symbol Structure
In general, Code 128 consists of seven sections:
Technical Data
GS1-128 is a standard developed by the GS1 organization based on Code 128. This standard defines a uniform syntax and semantics. The GS1-128 serves as a link between the data carrier and the data structure defined in the GS1 specification.
The main feature of the GS1-128 is the coding of data that goes beyond just product identification. For example, it can communicate an article number, a batch number and an expiration date all in one single GS1-128 barcode.
Due to the efficiency and flexibility of the GS1 system, it can be used in many areas, especially in the industrial or commercial sector.
Sub Variants, Derivatives
В отличие от штрих-кодов EAN-13 и EAN-8, штрих-код CODE-128 не имеет фиксированного количества символов, и в нем не используется контрольный символ.
Принципиальное отличие данного формата — возможность кодирования не только цифр, но и строчных или заглавных латинских букв, а также большого набора спецсимволов
Технические требования к символике штрихового кода Code 128, показатели символики, кодирование знаков данных, размеры, алгоритмы декодирования, параметры применения и строки-префиксы и идентификатора символики в России регламентируются ГОСТ 30743-2001 (ИСО/МЭК 15417—2000) «Автоматическая идентификация. Кодирование штриховое. Спецификация символики Code 128 (Код 128)».
Какие символы кодируются в штрих-код CODE-128?
В штрих-код CODE-128 можно закодировать до 70 символов:
Набор символов позволяет наносить на карту не только штрих-код с номером, например 00001, но и карточки, с обозначением идентификатора, содержащего буквенный префикс (например, AC0001) или полностью буквенные значения.
Внешний вид штрих-кода CODE-128
На рисунке, расположенном ниже, размещен пример штрих-кода с номером 00001 с различными вариантам отображения подписанного номера.
вы можете проверить
штрих-коды сосканировав их с экрана своим телефономCODE-128 С ПОДПИСАННЫМ НОМЕРОМ
Под штрих-кодом полностью отображен закодированный номер.
Введите символы и цифры:
Нажмите ввод
CODE-128 С ЧАСТИЧНО ПОДПИСАННЫМ НОМЕРОМ
Под штрих-кодом полностью отображена часть закодированного номера.
Введите символы и цифры:
Нажмите ввод
Отображать цифр справа:
CODE-128 БЕЗ ПОДПИСАННОГО НОМЕРА
Под штрих-кодом полностью отображен закодированный номер.
Введите символы и цифры:
Нажмите ввод
Структура Code 128
Структура штрих-кода Code128 достаточно проста. Он состоит из шести зон:
Символы Code128 состоят из трех штрихов и трех промежутков. Штрихи и промежутки имеют модульное построение. Ширина каждого модуля составляет от 1 до 4 модулей (1 модуль = 0,33 мм). Ширина знака равна 11 модулям. Остановочный (стоп) знак состоит из тринадцати модулей и имеет четыре штриха и три промежутка.
Контрольный знак Code 128
В спецификации Code128 использование контрольного знака является обязательным.
Контрольный знак вычисляется как сумма произведений весовых коэффициентов на соответствующие значения по модулю 103. Располагается контрольный знак между последним знаком данных и знаком «Stop».
Узнать стоимость и заказать карты со штрих-кодом
Малоизвестные факты о штрихкодах — загадочные цифры под штрихкодом
Время на прочтение
11 мин
Число зверя, штрихи смерти — насколько все это реально? Можно ли зашить в штрихкод видеоролик или фото голой Эммы Уотсон? Бывают ли “неправильные штрихкоды”, и что вообще значит “неправильный штрихкод”?
В “Клеверенсе” мы разрабатываем платформу Mobile SMARTS для создания мобильных решений по учету маркированного товара и постоянно сталкиваемся с детскими ошибками в маркировке. Обычно они вызваны простым нежеланием людей хоть немного разбираться в теме.
Наша платформа тоже не идеальна, но кое-что в своём деле мы понимаем. Статья не к тому, что типа мы крутые и разбираемся, а все вокруг не крутые и не разбираются, нет. У каждого свои задачи, мы тоже часто лажаем. Просто тема набирает популярность и выходит в массы, а любые ошибки стоят денег.
Сначала для затравки расскажем про кассовый штрихкод, а затем про загадочный GS1 DataMatrix, который используется в проекте тотальной маркировки товаров.
Сама статья больше развлекательная, всё изложенное при желании легко гуглится, но может и побудить кого-то изучить тему глубже.

Цифры под штрихкодом — что это такое? Знающие люди говорят, что тут всё просто: именно эти цифры “зашиты” в штрихкод. Девушка на кассе вбивает в программу цифры под штрихкодом — и вуаля — товар найден.
К сожалению, это заблуждение. Цифры под штрихкодом не “зашиты” в штрихкод. Для разговоров у камина сойдет, а для айтишника беда.
Надписи под штрихкодом называются Human readable interpretation (HRI). Одно только название уже должно наводить на мысль, что тут не всё в порядке.
В самом мягком варианте вера в то, что цифры под штрихкодом повторяют содержимое штрихкода — это примерно как верить в то, что название файла определяет его содержимое. Типа: “Переименовала ваш файл в .doc, но он всё равно не открывается”.
Рассмотрим подробнее, где тут собака зарыта.
Кассовый штрихкод
Пример про кассовый штрихкод — для затравки. Он на самом деле не вызывает никаких проблем, потому что за 50 лет использования в софте и оборудовании были вставлены 1000 костылей, чтобы обойти все проблемы (ну почти). Зато он хорошо иллюстрирует вопрос.
Вот в этих двух штрихкодах (EAN-13) ниже, под которыми написано “4601200000003” и “0123456789128”, в обоих нет штрихов для первой цифры. В первом штрихкоде нет штрихов для “4” (она закодирована другим способом), а во втором штрихкоде вообще в принципе нет лидирующего нуля, хотя он и напечатан под штрихкодом.


Да-да, именно первой цифры, а не последней (чексуммы) как можно было бы подумать. Последняя цифра (чексумма) в полосках этих штрихкодов как раз-таки есть, иначе затея с чексуммой не будет работать.
Рассмотрим поближе, что тут происходит.
В первом приведенном штрихкоде (“4601200000003”) в начале идут две длинные полосочки, они кодируют “начало штрихкода”, далее идут штрихи и пропуски для цифры “6”, затем про цифры “0”, “1”, “2”, “0” и “0”, две длинные полосочки в центре говорят про середину, затем пять одинаковых групп штрихов и пропусков кодируют “00000”, далее идут штрихи и пропуски для цифры “3” и завершающие две длинные полоски про конец штрихкода. Итого, в штрихкоде есть штрихи только про “601200000003”. Цифра “3” (последняя) в полосках штрихкода есть, а первой “4” нет! Откуда же взялась “4”?
Дело в том, что “4” закодирована грязным хаком. Для неё не хватает места, и вообще всё это большой исторический казус.
Изначально такие кассовые штрихкоды появились в США, там они состоят из 12 цифр и называются UPC (Universal Product Code). Для переноса технологии в Европу и адаптации стандарта Европе нужны были дополнительные цифры, потому что американские 12 все уже были заняты.

Первым товаром, приобретенным по штрих-коду на этикетке, стал блок из 10 жевательных резинок Wrigley Juicy Fruit. Это произошло в супермаркете Marsh города Трой (Огайо) в четверг, 26 июня 1974 года в 8.01 утра. В историю вошли и имя покупателя, и имя кассира, открывших новую страницу розничной торговли. Теперь упаковка жвачки, которая тогда обошлась в 67 центов, вместе с чеком хранятся в музее американской истории Смитсоновского института.
Чтобы расширить емкость, можно было бы просто добавить еще немного штрихов и пропусков, но в те времена это серьезно ухудшало считываемость. Поэтому вместо того, чтобы просто увеличить штрихкод в ширину, был применен “хак”.
По американскому стандарту любая из цифр штрихкода может быть записана: а) обычными штрихами и пропусками; б) их зеркальным отражением; в) инверсией черного и белого; г) зеркальной инверсией. Всё это нужно для того, чтобы можно было печатать инверсные штрихкоды (белым по черному) и сканировать штрихкод вверх ногами (зеркальное отражение в случае штрихкода — то же самое, что и поворот на 180°).
В “американском” штрихкоде (который на 12 цифр) первые 6 цифр кодируются обычными штрихами, а вторые 6 цифр инвертированными штрихами (где черные штрихи заменены на белые полоски и наоборот). Это сделано для того, чтобы понимать, перевернут штрихкод или нет, нормально я его сканирую или вверх ногами (и затем декодировать цифры в правильном порядке, а не задом наперед).
В новом “европейском” штрихкоде (который на 13 цифр), первая цифра (например, “4”) кодируется не штрихами, а путем «перетасовывания» способов кодирования следующих за ней 6 цифр из первого блока (второй блок из 6 оставили в покое).
Например, следующая за четверкой “6” выводится как обычно, штрихи следующего за ней “0” выводятся в обратном порядке (зеркально), следующие за ней “1” и “2” выводится снова в обычном виде, следующие два “0” снова зеркально. Общая длина штрихкода и число штрихов в результате этого трюка не меняется.
Для “американского сканера” такая белиберда не имеет смысла, а для Европы это тайный знак того, что в штрихкоде закодирована еще одна цифра! (да, мы всегда знали, что европейцы извращенцы).
Для всех цифр от “1” до “9” были придуманы такие правила тасовки способов кодирования. Для “0” ничего нет, т.е. 13-значный штрихкод с лидирующим нулем визуально ничем не отличается от 12-значного штрихкода без этого лишнего ноля (EAN-13 с лидирующим нулем эквивалентен UPC-А).
Из этого получается первый прикол, что если перед нами “американский” штрихкод (в котором варианты кодирования не “перетасованы”), то “американский сканер” читает 12 цифр, а условный “европейский сканер” может считать, что в нем есть лидирующий «0», и считывать лишний ноль (т.к. для кодирования ноля не предусмотрено никакой “перетасовки”, этого “лидирующего нуля” очевидно в принципе нигде нет в штрихкоде).
Конечно, мир давно глобализован, поэтому “американский” сканер и “европейский” сканер — это просто условности. Сканер один и тот же, но у него есть настройка: нужно ли ему в принципе считывать EAN-13 (Европа) или читать только UPC-А (США), а если считывать EAN-13, то надо ли добавлять лишний ноль к американским штрихкодам UPC-А.
С этим связана одна распространенная проблема при внедрении штрихкодирования: когда в базе данных у компании либо нет нолей в начале штрихкодов, а сканер считывает с “лишним” нолем, либо наоборот, в базе данных есть ноль в начале, а сканер его “не считывает” (хотя, что там считывать, — этого ноля в принципе в штрихкоде нет).
Казалось бы, сложно накосячить в использовании EAN-13/UPC. Тем не менее, люди делают следующие ошибки:
В наших программных продуктах, таких как “Магазин 15” или “Склад 15”, построенных на платформе Mobile SMARTS, мы решаем эту проблему очень просто: сканер устройства всегда автоматически настраивается на возврат ноля, а поиск товара по базе данных производится два раза: и с нолем, и без ноля (чтобы уж точно найти товар).
Сканер мы стараемся настраивать программно, без участия человека. Если сканер нельзя настроить программно — то это всегда проблема, потому что по умолчанию сканером может обрезаться не только 0 (который в начале), но еще и чексумма (которая в конце), тогда в программу придут не 13, а уже 11 символов, зачастую даже без указания типа штрихкода (такие замечательные сканеры тоже бывают).
В этом случае мы бессильны улучшить результат. 11 символов могли прийти от сканирования любого другого типа штрихкода, мы не можем считать все штрихкоды как EAN-13. Чтобы настроить сканер, человеку придется сканировать с листа настроечные штрихкоды или заходить в какие-нибудь меню, а всё это — источники ошибок.
GS1 DataMatrix
Этот пример стал популярным благодаря введению обязательной маркировки товаров. История полна граблей, велосипедов и трупиков мелких животных, как сарай вашей бабушки.
Ну ладно, допустим с EAN-13 можно придраться и сказать, что первая цифра всё-таки есть в штрихкоде, просто она закодирована не совсем штрихами (хотя для лидирующего “0” это и не так).
Возьмем тогда другой пример, штрихкод GS1 DataMatrix «(21)abba01(01)04601200000003»:

В этом штрихкоде “внутри” нет ни скобок, ни символа «0», ни буквы «a», ни переноса строки.
Что тут происходит?
Во-первых, никакие скобки в штрихкод не кодируются, они печатаются только для удобства прочтения человеком. Это снова называется Human readable interpretation (HRI), привет, кожаный мешок.
Во-вторых, в штрихкоде есть специальные управляющие символы, которые должна расставить та программа, которая формирует данные для штрихкода. Не какая-то бесплатная opensource программа, написанная умными очкариками, а ваша программа, та самая, которую пишете Вы, мой друг. В этот раз символы, которые нужно вставить, не имеют отношения к “коррекции” и т.п., а размечают данные, которые нужно закодировать в штрихкод.
В самом начале в штрихкод вставляется управляющий символ, который называется FNC1 и имеет код 232, что соответствует либо странному печатаемому символу «Þ» (ANSI), либо русской букве “и” (Windows-1251), смотря какую кодировку использовать. Этот символ говорит, что у нас не просто абы какой DataMatrix, а именно GS1 DataMatrix, данные в котором имеют определенный формат: массив данных из пар (“код поля”, “значение поля”).
Этот управляющий символ FNC1 попадает в самое начало штрихкода, но его нельзя “передать” в штрихкод в составе данных.
Кроме того, непечатаемые символы, вполне очевидно, нельзя копипастить в составе строки, хаха! Страдай, кожаный мешок!
Указание, нужен префикс или не нужен, обычно передают как отдельную настройку (галочку) в программу формирования штрихкода. Если передать префикс как часть данных, то получим либо ошибку, либо два префикса в штрихкоде (в зависимости от используемой программы).
Далее, поскольку в штрихкоде внутри нет скобок, то уже непонятно, где кончается одно поле и начинается другое, где тут номера полей. Без скобок получается “21abba010104601200000003” (тут “01” встречается три раза, ха-ха).
Где заканчивается “01” из значения поля (21) и начинается настоящее (01)?
Это решается следующим способом:
По стандарту GS1 поля имеют формат. Не абы что, а формат значения. Например, значение для (01) должно состоять из 14 цифр и баста (нельзя 13 цифр, нельзя 12 цифр, нельзя не цифры). А поле (21), наоборот, имеет переменную длину, разрешены цифры, латинские буквы обоих регистров, знаки препинания и даже (опачки!) скобки.
Если после значения для (21) штрихкод не закончился, и там еще что-то есть, то в данные вставляется разделитель (это может быть снова или FNC1, или непечатаемый символ GS с кодом 29).
А общее правило звучит так: спецсимвол GS не вставляется, только в случае если AI начинается с пары цифр из этой вот таблицы:
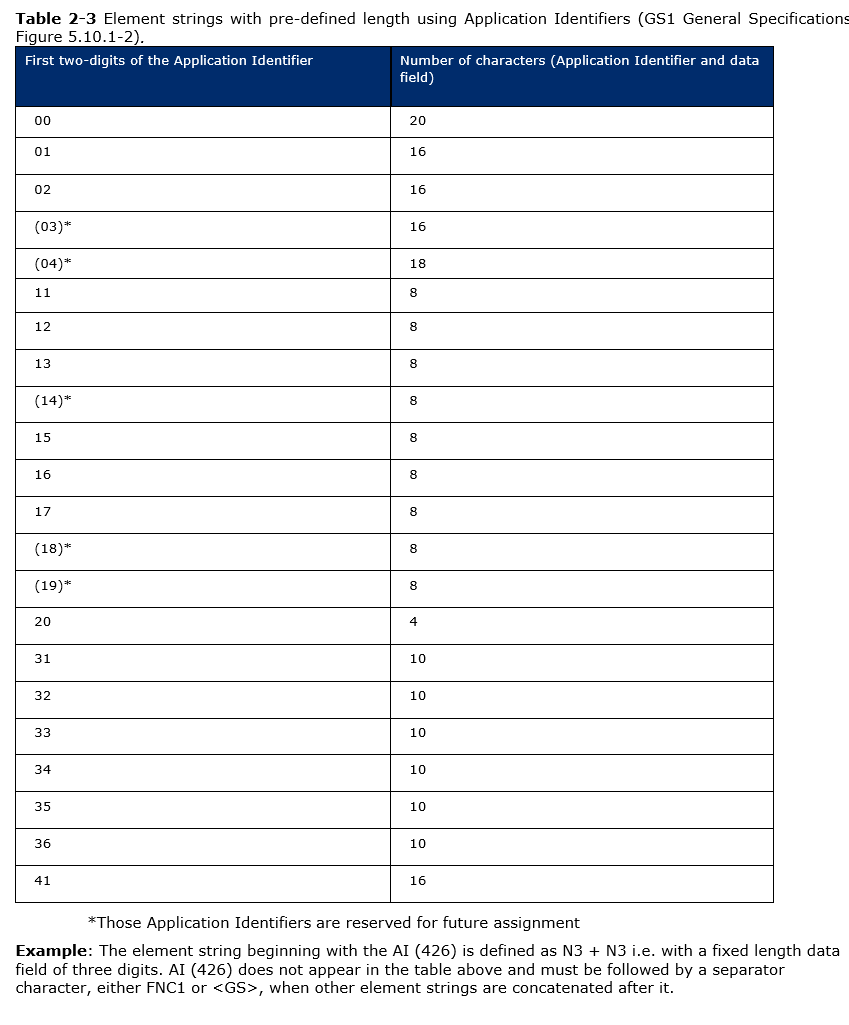
Для всех остальных полей GS1 (не из этой таблицы) в конце значения нужно вставлять GS.
Т.е., мы получим “FNC121abba01GS0104601200000003” (только помним, что первый FNC1 мы не будем передавать в программу формирования штрихкода, а второй GS — это не строка “GS”, а один символ с кодом 29).
Эти требования — именно про данные, а не про штрихкод DataMatrix, потому что в штрихкод DataMatrix можно положить любые данные, они прекрасно закодируются и прочитаются. Тут речь о GS1 DataMatrix, который имеет определенный формат, и ваша программа должна соблюсти этот формат, прежде чем подавать данные в штрихкод.
Вообще говоря, в мире существуют программы печати штрихкодов, которым можно скармливать данные со скобками и они сами всё разрулят. Но это специализированный софт, который стоит денег, а не тот бестолковый и бесплатный онлайн-генератор штрихкодов, которым вы пользуетесь.
И наконец. То, как это будет напечатано и то, как это будет отсканировано, — две большие разницы. То, как данные печатаются под штрихкодом, и как они передаются сканером — это в чистом виде настройки принтера и сканера.
В нашем примере мы закодировали в штрихкод поля порядке: сначала (21), потом (01), а на изображении под штрихкодом распечаталось сначала (01), потом (21). Это снова называется Human readable interpretation (HRI), и порядок вывода в подписи соответствует правилу “потому что так принято”.
Сканер штрихкодов тоже имеет свои настройки, которые заставляют его переставлять поля, вставлять скобки и другие символы, переносить строки и т.п.
В большинстве случаев сканер прочитает наш штрихкод как “21abba01GS0104601200000003”. Никакого лидирующего FNC1, никаких скобок, GS не печатаемый и не виден в “Блокноте” (нужно использовать хотя бы Notepad+).
И принтер, и сканер могут делать со штрихкодами что хотят: добавлять и убирать символы, менять их местами — ради соответствия гайдлайну или для совместимости со сторонней программой.
Что еще интересно: в этом штрихкоде только 16 байт данных (на 24 символа без скобок).
Вот что тут происходит:
Т.е. чтобы закодировать “a”, нужно записать в штрихкод “b”, чтобы закодировать “1”, нужно записать “2” и т.д., именно поэтому прямо в самом штрихкоде нет байта 97 (значение буквы “a” в ASCII).
Итого, в приведенном штрихкоде “закодировано” в байтах 232, 151, 98, 99, 99, 98, 131, 232, 131, 134, 190, 142, 130, 130, 130, 133. И это еще до кодов коррекции и паддинга!
Непонимание процесса кодирования приводит к тому, что, например, для начавшейся обязательной маркировки обуви люди печатают на принтер неправильно сформированные данные и получают неправильные штрихкоды, которые выглядят вполне нормально, читаются приложением “Честный знак”, но данные в них неверные, как минимум это не GS1 DataMatrix.
Штрихкоды неправильно напечатаны, неправильно читаются, и такая обувь не считается правильно промаркированной.
В своем софте “Кировка” мы боремся с этим следующим образом: для печати принимаем в качестве исходных данных любой мусор, пытаемся распарсить его как GS1 DataMatrix, разбираем на косточки. Если всё прошло удачно, то конвертируем в правильный формат, чтобы принтер это понял; а при сканировании перепроверяем данные от сканера, делая таким образом вывод о правильности печати.
Для этого нам, конечно, приходится работать на нативном уровне и со сканером мобильных устройств, и с принтерами, чтобы всё это было правильно ими интерпретировано, а мы собирали максимально полную информацию.
Выполним еще одно упражнение: посмотрим, какого размера должен быть штрихкод GS1 DataMatrix для хранения кода маркировки обуви и легпрома.
На сайте «Честного знака» написано, что код маркировки обуви должен содержать следующие поля (для легпрома те же требования):
Для каждого из этих полей в данных для штрихкода должен быть указан идентификатор применения GS1 (AI, application identifier).
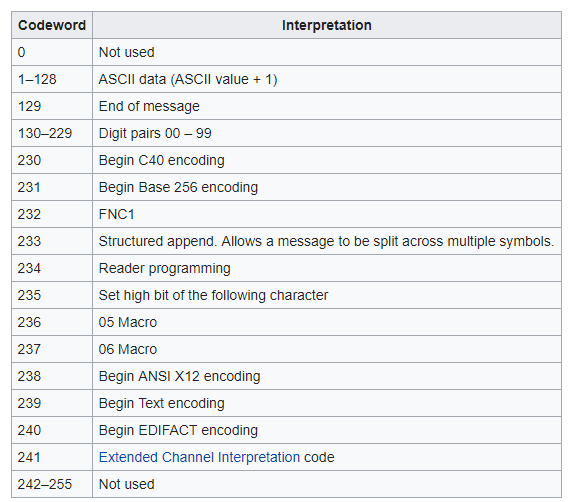
Таблица codeword для DataMatrix
Таблица, объясняющая кодирование КМ обуви в DataMatrix:
Как видно, размер данных в теории может меняться в широких пределах от 68 до 118 байт. На практике разброс меньше, длина ближе к 118, потому что в серийном номере и в криптокоде мало цифр и много знаков препинания, включая скобки.
Согласно GS1 DataMatrix Guideline, такие данные укладываются в штрихкоды размером от 36х36 до 44х44 (колонок и строк битов, не миллиметров). В миллиметрах размер будет зависеть от разрешающей способности принтера (обычно это 203-600 dpi).
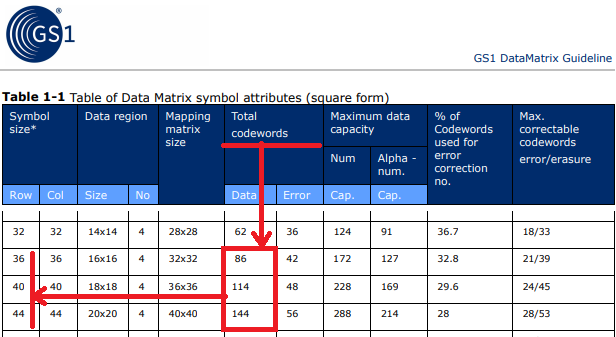
Таблица из GS1 DataMatrix Guideline
А как же голая Эмма Уотсон? Рассмотрим в следующей статье.