
Главная | Случайная страница | Трендовая
- Основные характеристики кодов
- Классификация кодов и их характеристика.
- Основные свойства линейных кодов
- Главные характеристики качественного кода
- Плохой код делает слишком много, чистый код сфокусирован
- Язык, на котором вы написали код, должен выглядеть как будто его создали для решения этой проблемы.
- Не нужно избыточности
- Читать ваш код должно быть приятно
- Другой разработчик может легко расширить ваш код
- Нужно минимизировать зависимости
- Меньше — лучше
- Необходимы юнит- и приемочные тесты
- Код должен быть выразительным
- Так что же такое чистый код?
- Математические аспекты хорошего кода
- Введение
- Качество
- Гармония
- Целостность
- Интегральная характеристика
- Размеры
- Заключение
- Начало
- 1 Речь, мимика, жесты
- 2 Чередующиеся сигналы
- 3 Контекст
- Кодирование текста
- 1 Блочное кодирование
Основные характеристики кодов
Основание кода. Коды характеризуются числом ( m ) используемых различных качеств элементов кода, т.е. числом символов, или букв, кодового языка. При m = 2 имеет место двузначный (бинарный) код, при m = 3 — трехзначный код и т.д.
Разрядность кода ( n ) есть число символов в кодовой комбинации (длина кодового слова). Если длина всех кодовых слов одинакова ( n = const ), код называется равномерным.
Мощность кода есть число кодовых комбинаций Np, используемых для передачи сообщений, из общего числа всех возможных кодов и комбинаций N = m n .
Если N p < N, то код обладает избыточностью, так как не все кодовые комбинации используются для передачи сообщений. С избыточностью связана способность кода к обнаружению ошибок, так как для этой цели используются ( N p – N ) неразрешенных кодовых комбинаций. Избыточность кода характеризуется коэффициентом избыточности :
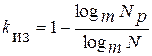 . ( 1 )
. ( 1 )
Диапазон возможных значений коэффициента избыточности для разных кодов 0 < kиз < 1. При kиз = 0 имеет место безизбыточный непомехозащищенный код.
Кодовое расстояние d между двумя кодовыми комбинациями определяется сложением по модулю 2 единиц в табличных записях кода. Операция производится без переноса единицы в старший разряд и обозначается 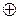 .
.
При сложении по модулю два получим:
1 1 = 0 ; 0 0 = 0 ; 1 0 = 1 ; 0 1 = 1.
Для двухзначных кодов d есть вес, т.е. число единиц, суммы по модулю 2 двух кодовых комбинаций. Например,
0110111 – 1 кодовая комбинация
1101010 – 2 кодовая комбинация
1011101 – сумма по модулю 2
Число единиц в сумме (вес суммы) равно кодовому расстоянию d = 5.
Кодовое расстояние между различными кодовыми комбинациями, как правило, различно. Минимальное кодовое расстояние d min характеризует помехозащищенность кода.
Распределение рабочих кодовых комбинаций по кодовым расстояниям характеризует потенциальную помехозащищенность кода. Рассмотрим эту характеристику кода на примере. Пусть код содержит следующую совокупность кодовых комбинаций (кодовых векторов): V1 = 001, V2 = 010, V3 = 011, V4 = 100. Найдем кодовые расстояния d ij между всеми кодовыми векторами и сведем их в табл. 1.
Определим и сведем в табл. 2 распределение рабочих кодовых комбинаций рассматриваемого примера по кодовым расстояниям, т.е.
Из таблицы ясно, что, например, кодовый вектор V1 отстоит от одного из векторов на d = 1 и от двух других на d = 2, а вектор V3 отстоит от двух векторов на d = 1 и от одного на d = 3. Коды, для которых N( d )p различно для разных кодовых векторов, называются несимметричными. Если N( d )p для всех рабочих кодовых векторов одинаково, то код называется симметричным.
Для рассматриваемого кода минимальное кодовое расстояние между рабочими векторами d min = 1. Это означает, что даже единичная ошибка может привести к ложному (не обнаруживаемому) переходу одного кодового вектора в другой, следовательно, имеется вероятность приема ложного сообщения при искажении из-за наличия помех качественного признака одного из n элементов кодовой комбинации.
Помехоустойчивость характеризуется показателем S , который рассчитывается по формуле
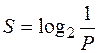 , ( 2 )
, ( 2 )
где Р — вероятность ошибки (выполнения ложных сообщений).
Вероятность ошибки определяется отношением
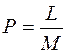 , ( 3 )
, ( 3 )
где L — количество выполненных ложных сообщений,
М — общее количество допустимых сообщений.
Потенциальная помехозащищенность кода характеризуется коэффициентами ложных переходов одной кодовой комбинации в другую под влиянием помех кратности d.
Коэффициент ложных переходов определяет вероятность ложного перехода одной рабочей кодовой комбинации в другую под влиянием помех кратности d и определяется выражением
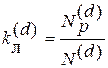 , ( 4 )
, ( 4 )
где N( d ) — общее число кодовых векторов, отстоящих от данного вектора на кодовое расстояние d , N( d )p – число рабочих кодовых векторов, отстоящих от данного вектора на кодовое расстояние d .
Для симметричных кодов N( d )p одинаково для всех рабочих кодовых векторов, и 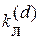 определяется согласно ( 4 ). Для несимметричных кодов коэффициент ложных переходов при d – кратной ошибке определяется как среднее значение этого коэффициента для всех N p рабочих кодовых векторов, т.е.
определяется согласно ( 4 ). Для несимметричных кодов коэффициент ложных переходов при d – кратной ошибке определяется как среднее значение этого коэффициента для всех N p рабочих кодовых векторов, т.е.
Общее число кодовых векторов N( d ) отстоящих друг от друга на кодовое расстояние d, для двузначных кодов может быть определено как число сочетаний по d из числа разрядов кода n , т.е.
Для рассматриваемого выше примера кода
для d = 1 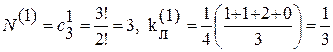 ,
,
для d = 2 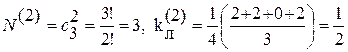 ,
,
для d = 3 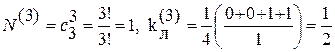 .
.
Таким образом, при однократной ошибке вероятность приема ложного сообщения 1/3, при двух- и трехкратной ошибке вероятность ложного приема 1/2.
Очевидно, чем больше d min , тем выше помехозащищенность кода, так как при кратности ошибки меньше d min , переход одной рабочей кодовой комбинации в другую невозможен. Следовательно, не будет и ложного приема информации. Искаженная помехами кодовая комбинация легко обнаруживается, так как она не принадлежит к числу рабочих комбинаций. Таким образом, при d min = r + 1 обнаруживаются все ошибки кратности r . При d min = 2 s + 1 могут быть исправлены все ошибки кратности s , а при d min = r + s +1 (при r ³ s) обнаруживаются ошибки кратности r и исправляются ошибки кратности s .
Главная | Случайная страница | Трендовая
Классификация кодов и их характеристика.
Аналоговые и разделительные коды.
Аналоговый код – это представление значений на продолженной шкале без четкого разделения на элементы, а разделительный – это код, который четко отделяет одно значение от другого.
Так, на часах все минуты разделены чертой. Аналоговый код – это континуальный циферблат с обозначениями, которые не являются слишком дробными.
Фотография аналоговым способом копирует натуру, а 60 линий на циферблате часов отображают вращение земли вокруг своей оси с помощью разделительного кода.
Восприятие реальности является процессом раскодирования.
Он включает идентификацию элементов и понимание связей между ними. Наше восприятие реальности аналогично языку по отношению к культуре. В этом смысле мы говорим о реальности, как социальном конструкте. С помощью кодов мы конструируем ее значения, но не произвольно, а используя ее реальные свойства.
Репрезентационные и презентационные коды.
Репрезентационные коды используются для производства текстов, т. е. сообщений независимого существования из иконических и символических знаков.
Презентационные коды индексичны. Они не могут существовать отдельно от коммуникатора и социальной ситуации, в которой осуществляется коммуникация, как, например, в невербальной коммуникации. Жесты, движение глаз и интонация голоса.
Возможно преобразование презентац. кодов в репрезентац. Написанный текст может иметь «голосовой фон», а фото под тестом – говорить об эмоциях.
Сложные и простые коды.
Речь идет о социально-профессиональном уровне коммуникатора (различия в речи у людей из низших и высших слоев общества).
— простота и сложность выражаются в объеме словарного запаса, построения предложений.
— простой код тяготеет к устному и таким образом, ближе к презентационным индексичным кодам. Сложный код может быть и устным и письменным и лучше подходит для репрезентац., символических сообщений.
— простой код – субъективность, сложный – объективность, точность.
— сложный – индивидуальность, личностные свойства. Простой – основано на общих мыслях.
— культурный опыт.
В обществе высоко ценятся сложные коды, но нельзя отрицать и значимость простых. Каждый является и личностью, и членом группы, и нуждается в обоих типах языков, как в описании, так и анализе ситуаций.
Массовые и специальные коды.
Массовые коды относятся к простым, они обращены к непосредственному восприятию и не требуют образования для их понимания. Они ориентированные на общество, на общее мнение и интересы, Таковые, например, коммуникация между болельщиками на футболе или участниками митинга.
Специальные коды схожи со сложными. Они опираются не на общий, а на образовательный и интеллектуальный опыт. От коммуникатора здесь требуется больше знаний или своя оригинальная позиция. Аудитория нуждается в обогащении и развитии, в то время как массовая хочет подтверждения и убеждения.
Логические и условные коды
Логические коды – символичные, обозначающие, безличностные и статичные. Невозможны искажения в математике (2*2=4).
Отличие логического и условного кодов в различной природе их парадигм. У первых – определенные, четкие, ограниченные парадигмы, обозначающие смысл.
Условные коды открыты, могут дополняться. По ним может не быть полного согласия. Они более динамичны и способны изменяться (культура).
Теория значения Ч. Осгуда.
Любое реальное действие может вызывать приятные и неприятные реакции, оценки, ассоциации, т. е. коннотации. Ч. Осгуд пытался объяснить, из чего эти коннотации состоят и как они возникают.
Коннотация возникает не только при восприятии физических объектов. Мы формируем значения и для знаков объектов (слов, жестов), исходя из внутренних предпочтений. Большинство значений изучается не как результат прямого опыта с естественным стимулом, а как ассоциация между одним знаком и другим. Здесь не обязателен даже физический контакт, например, когда мы воспринимаем рекламу или ПР-материалы.
Метод семантического дифференциала.
Ч. Осгуд разработал метод измерения значений, называемый семантическим дифференциалом. Пытаясь найти главные значения, он пришел к идее семантического пространства, на основе трех измерений: общей оценки, а так же активности и потенциала человека.
С помощью метода семантического дифференциала возможно эмпирическое измерение значений (смыслов).
По сути, это был метод изучения, эмоций и позиций людей в связи с их социокультурным опытом.
Метод относительности прост и включает три стадии.
— Вначале надо выявить характеристики, которые требуются исследовать и выразить их в виде бинарно противопоставленных понятий на пяти-семичленной шкале. Обычный набор включает 8-15 ценностей.
— затем проводится опрос группы.
— далее подсчитываются средние величины.
При изучении восприятия рекламы с помощью семантического дифференциала могут оцениваться ее цвет (яркость-невзрачность), композиция (четкая — хаотичная), цель (ясная – неясная), оригинальность, информативность, эстетичность и другие характеристики. Аналогичное место может использоваться при оценке акций ПР.
Вопрос 20. Коммуникация как дискурс. Виды дискурсов. Конверсационный анализ.
Коммуникация как дискурс
Коммуникация, в основном, состоит из комплексных актов, формирующих сообщения, что и составляет содержание дискурса. Одно из важнейших условий хорошего дискурса связано с использованием знаков и языка когерентным, согласованным образом.
Дискурсный анализ позволяет увидеть, как сообщения создаются, используются и понимаются. Структура дискурса меняется в зависимости от того, что мы хотим сделать, сообщить. Дискурсный анализ дает возможность проверить различные пути осуществления действий через сообщения. Его предметом является чаще всего естественно происходящий разговор.
Скотт Якоб выявляет три типа проблем в дискурсном анализе:
— проблему значения. Как люди понимают сообщение? Какая информация заложена в структуре утверждения? Например: он здесь? Это значит, что вы хотите говорить с человеком по телефону или пригласить его в кабинет из приемной.
— проблему действия. Как сделать так, чтобы разговор шел на уровне общего понимания или эмоционального доверия.
— проблему согласия. Как сделать так, чтобы разговоров шел на уровне общего понимания или эмоционального доверия.
Типы иллокутивных (речевых) актов:
— утверждение – защита говорящим перед слушателем истинности сообщения.
— директива (распоряжение – склонение слушателя к действию
— заверение – обращение говорящему к будущему.
— экспрессия – сообщение психологического состояния
— декларация – подтверждение того, что делается.
Рассматривая дискурс с позиции отношения между участниками коммуникации, В.И. Карасик выделяет личностно-ориентированное и статусно-ориентированное (институциональное) общение.
Мы говорим о личностно-ориентированном общении, если собеседник нам хорошо известен, и он интересует нас во всей полноте своих характеристик. В случае статусно-ориентированного общения коммуниканты реализуют себя в ограниченном наборе ролевых характеристик, выступая в качестве представителей определенных групп людей (начальник, подсудимый, клиент, пациент, учитель, коллега и т. д.). Личностно-ориентированный дискурс представлен в двух основных разновидностях: бытовой и бытийный, статусно-ориентированный дискурс – в нескольких типах институционального общения, выделяемых на основании функционирующих в обществе социальных институтов.
В.И. Карасик выделяет следующие виды институционального дискурса:
Институциональный дискурс, по мнению В.И. Карасика, «есть специализированная клишированная разновидность общения между людьми, которые могут не знать друг друга, но должны общаться в соответствии с нормами данного социума».
В классификации В.И. Карасика, персональный дискурс представлен двумя основными разновидностями — бытийный и бытовой (обиходный) дискурс
Бытийный дискурс носит развернутый характер, попытка передать всю красоту внутреннего мира говорящего. В нем используются все формы речи на базе литературного языка. «Бытийное общение носит преимущественно монологический характер и представлено произведениями художественной литературы и философскими и психологическими интроспективными текстами»
Опосредованный бытийный дискурс — это «это аналогическое (переносное) и аллегорическое (символическое) развитие идеи через повествование и описание. Повествование, в свою очередь, представляет собой изложение событий в их последовательности, а описание — статическая характеристика очевидных, наблюдаемых явлений.
В отличие от бытийного, бытовой дискурс, как правило, представлен в виде диалога. Общение протекает между хорошо знакомыми людьми, поэтому оно происходит на сокращенной дистанции и пунктирно. Так как участники диалога хорошо знакомы, они понимают друг друга с «полуслова». В таком общении зачастую детали разговора не проговариваются. Именно для этого типа дискурса справедливо высказывание И. Н. Горелова: «Вербальное общение лишь дополняет невербальное, а основная информация передается мимикой жестикуляцией и т.д.». Специфика бытового общения детально отражена в исследованиях разговорной речи. Бытовое общение является естественным исходным типом дискурса, органически усваиваемым с детства. Фонетически здесь является нормой нечеткое беглое произношение. Общаясь на бытовом уровне, люди прибегают к сниженной и жаргонной лексике. Важнейшей характеристикой единиц разговорной речи является их конкретная денотативная направленность, эти слова указательны по своему назначению (именно потому они и легко заменяются невербальными знаками), кроме того, в узком кругу хорошо знакомых людей реализуется лимитивная (ограничивающая, парольная) функция общения, коммуниканты используют те знаки, которые подчеркивают их принадлежность к соответствующему коллективу (семейные, групповые слова) и непонятны посторонним. Бытовой дискурс отличается тем, что адресат должен понимать говорящего с полуслова. Активная роль адресата в этом типе дискурса предоставляет отправителю речи большие возможности для оперативного переключения тематики, а также для легкого перевода информации в подтекст (ирония, языковая игра, намеки и т.д.).
Анализ повседневных разговоров – это часть этнометодологии, которая изучает процесс организации людьми своей повседневной жизни. Она включает в себя ряд методов для наблюдения того, как люди самоорганизуются.
Беседа рассматривается пункт за пунктом. Главная проблема – это согласованность (когерентность) в беседе, т. е. связанность значений, смысла. Когерентная беседа понимается всеми и приводит получению результата, через переговоры. Конверс. Анализ раскрывает детально суть этих результатов. Анализируется последовательность организации (порядок) или методы организации разговора.
Важен принцип кооперации – каждый должен внести свой клад в беседу.
Есть 4 правила достижения кооперации:
— количества – вклад каждого не малый и не слишком большой.
— качества – честность.
— релевантности – уместность вклада
— стиля – участие каждого должно быть понятным, недвусмысленным.
Использование локальности. Беседа – это серия речевых актов, каждый из которых связан с предыдущим. «Как дела? – Нормально! ». Пара речеовго акта. Возможны следующие пары:
— согласие – несогласие
— вопрос – ответ
— вызов – ответ
— приветствие – приветствие
— требование – отказ (согласие)
— оскорбление – ответ
— поддержка – отказ (согласие)
— комплимент – принятие (непринятие)
— обвинение – отрицание (признание)
— хвастовство – осмеяние и др.
Использование глобализма или рационально – прагматический подход. Беседа – это практическое действие, которое преследует цель. Чтобы достигнуть ее, необходимо аргументировать пути, средства. В таком случае согласованность беседы зависит от рациональной, т.е. наибольее эффективной, игры.
Главное возражение конверсационному анализу состоит в том, что исследователь наблюдает и делает заключения на основе текста безотносительно к внешним факторам или даже к мнениям участников. Он опирается в анализе дискурса только на свою интуицию как представителя определенной культуры. Некоторые полагают, что когерентность заключена не в тексте, а в когнитивной системе воспринимающего, и зависит от ее применения в дискурсе. Другие говорят об идеологическом и властном влиянии. Важны также свойства коммуникатора и социальной ситуации.
Вопрос 21. Психогеометрические характеристики личности. Личностный образ коммуникатора. Основные репрезентативные системы и способы » подстройки» к партнеру. Соционическая классификация личности.
Главная | Случайная страница | Трендовая
Основные свойства линейных кодов
1. Произведение любого кодового слова 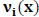 на транспонированную проверочную матрицу дает нулевой вектор размерности
на транспонированную проверочную матрицу дает нулевой вектор размерности 
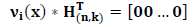
2. Произведение некоторого кодового слова 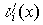 , т.е. с ошибкой, на транспонированную проверочную матрицу называется синдромом и обозначается Si(x) Термодинамический потенциал Гиббса Лекции по физике
, т.е. с ошибкой, на транспонированную проверочную матрицу называется синдромом и обозначается Si(x) Термодинамический потенциал Гиббса Лекции по физике
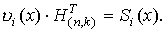
3. Между порождающей и проверочной матрицами в систематическом виде существует однозначное соответствие, а именно:

4. Кодовое расстояние d0 (n, k) — кода равно минимальному числу линейно зависимых столбцов проверочной матрицы
Пример.
для кода (5, 3):

для кода (5, 2):
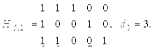
5. Произведение информационного слова на порождающую матрицу дает кодовое слово кода
Пример. для кода (5, 3)
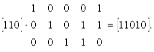
6. Два кода называются эквивалентными, если их порождающие матрицы отличаются перестановкой координат, т.е. порождающие матрицы получаются одна за другой перестановкой столбцов и элементарных операций над строками.
7. Кодовое расстояние любого линейного (n, k) — кода удовлетворяет неравенству 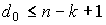 (граница Сингтона). Линейный (n, k) — код, удовлетворяющий равенству
(граница Сингтона). Линейный (n, k) — код, удовлетворяющий равенству 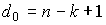 , называется кодом с максимальным расстоянием.
, называется кодом с максимальным расстоянием.
Кодирование, минимизирующее избыточность кода, называется оптимальным
Вопрос существования таких кодов составляет суть одной из основных теорем теории информации – теоремы кодирования, доказанной К. Шенноном. Приведем одну из эквивалентных формулировок данной теоремы.
Теорема кодирования. Сообщения произвольного источника информации Z с энтропией H(Z) всегда можно закодировать последовательностями в алфавите B, состоящем из M символов, так, что средняя длина кодового слова lср будет сколь угодно близка к величине 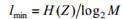 , но не меньше нее.
, но не меньше нее.
Доказательство этой теоремы в силу его сложности не рассматривается. Теорема утверждает, что разность (lср – lmin) можно сделать как угодно малой. В этом и заключается задача методов оптимального кодирования. Вернемся к рассмотрению алфавитного источника информации, генерирующего сообщения в символах алфавита А. Поскольку избыточность кода L задается формулой
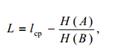
Метод Шеннона – Фано
Шаг 1. Упорядочиваем символы исходного алфавита в порядке невозрастания их вероятностей. (Записываем их в строку.)
Шаг 2. Не меняя порядка символов, делим их на две группы так, чтобы суммарные вероятности символов в группах были по возможности равны.
Шаг 3. Приписываем группе слева » 0″, а группе справа » 1″ в качестве элементов их кодов.
Шаг 4. Просматриваем группы. Если число элементов в группе более одного, идем на Шаг 2. Если в группе один элемент, построение кода для него завершено.
Рассмотрим работу описанного алгоритма на примере кодирования алфавита 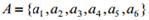 , символы которого встречаются с вероятностями (0, 25; 0, 05; 0, 25; 0, 1; 0, 25; 0, 1) соответственно. Результат кодирования изображен на рис. 5.1.
, символы которого встречаются с вероятностями (0, 25; 0, 05; 0, 25; 0, 1; 0, 25; 0, 1) соответственно. Результат кодирования изображен на рис. 5.1. 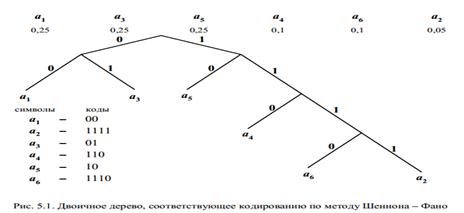
Очевидно, что процесс построения кода в общем случае содержит неоднозначность, так как мы не всегда можем поделить последовательность на два равновероятных подмножества. Либо слева, либо справа сумма вероятностей будет больше. Критерием лучшего варианта является меньшая избыточность кода. Заметим также, что правильное считывание кода – от корня дерева к символу – обеспечит его префиксность.
Шаг 1. Упорядочиваем символы исходного алфавита в порядке невозрастания их вероятностей. (Записываем их в столбец.)
Шаг 2. Объединяем два символа с наименьшими вероятностями. Символу с большей вероятностью приписываем » 1″, символу с меньшей – » 0″ в качестве элементов их кодов.
Шаг 3. Считаем объединение символов за один символ с вероятностью, равной сумме вероятностей объединенных символов.
Шаг 4. Возвращаемся на Шаг 2 до тех пор, пока все символы не будут объединены в один с вероятностью, равной единице.
Закодируем тот же 6-буквенный алфавит методом Хаффмана, изобразив соответствующее двоичное дерево (рис. 5.2).
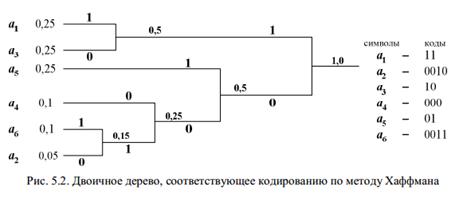
Считывание кода идет от корня двоичного дерева к его вершинам с обозначением символов. Это обеспечивает префиксность кода. Метод Хаффмана также содержит неоднозначность, поскольку в алфавите могут оказаться несколько символов с одинаковой вероятностью, и код будет зависеть от того, какие символы мы будем объединять в первую очередь. Мы видим, что код Шеннона – Фано и код Хаффмана для заданного алфавита отличаются. На вопрос, какой из них лучше, даст ответ проверка на оптимальность.
Описанные методы легко применить не только для двоичного кодирования, но и для кодирования алфавитом, содержащим произвольное число символов M. В этом случае в методе Шеннона – Фано идет разбиение последовательности символов на M равновероятных групп, в методе Хаффмана – объединение в группы по M символов.
Проверка кода на оптимальность.
Для оценивания оптимальности кода используют разные критерии. Основным показателем является коэффициент относительной оптимальности kопт, вычисляемый по формуле,
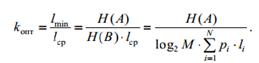
Из теоремы кодирования следует, что эта величина не превышает единицы. И чем меньше она отличается от единицы, тем более эффективным считается код.
Следующая характеристика оптимальности кода обусловлена оценкой распределения символов кодового алфавита: код тем ближе к оптимальному, чем меньше различаются вероятности появления различных символов кодового алфавита в закодированном сообщении. Среднее число появлений 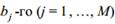 символа кодового алфавита можно оценить по формуле
символа кодового алфавита можно оценить по формуле
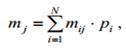
где N – объем кодового алфавита;
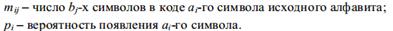
В последние годы усиленно разрабатываются сверточные коды. Формирование проверочных символов в таких кодах осуществляется по рекуррентным правилам, поэтому сверточные коды часто называют рекуррентными или цепными. Особенностью сверточных кодов является то, что они формируются непрерывно, и в них проверочные символы перемежаются с информационными по всей длине кодовой последовательности, подчиняясь одному и тому же рекуррентному соотношению. Максимальное число информационных символов, участвующих в формировании каждого выходного символа сверточного кода, определяемое числом ячеек регистра сдвига, носит название длины кодовых ограничений. Эта характеристика близка по смыслу к длине блока информационных символов для блочных кодов.
Непрерывные коды не разбиваются на блоки. Операции кодирования и декодирования производятся над непрерывной последовательностью символов. Самые распространенные и удобные для практического применения среди непрерывных — сверточные коды.
В непрерывных кодах процесс кодирования и декодирования носит непрерывный характер. Каждый избыточный ( проверочный) символ формируется по двум или нескольким информационным символам. Проверочные символы размещаются в определенном порядке между информационными символами исходной последовательности. Этот класс кодов появился совсем недавно и не получил пока широкого развития.
Циклический код — линейный код, обладающий свойством цикличности, то есть каждая циклическая перестановка кодового слова также является кодовым словом. Используется для преобразования информации для защиты еѐ от ошибок
Циклические коды составляют большую группу наиболее широко используемых на практике линейных, систематических кодов. Их основное свойство, давшее им название, состоит в том, что каждый вектор, получаемый из исходного кодового вектора путем циклической перестановки его символов, также является разрешенным кодовым вектором. Принято описывать циклические коды (ЦК) при помощи порождающих полиномов G(Х) степени m = n – k, где m – число проверочных символов в кодовом слове. В связи с этим ЦК относятся к разновидности полиномиальных кодов. Операции кодирования и декодирования ЦК сводятся к известным процедурам умножения и деления полиномов. Для двоичных кодов эти операции легко реализуются технически с помощью линейных переключательных схем (ЛПС), при этом получаются относительно простые схемы кодеков, в чем состоит одно из практических достоинств ЦК.
Эффективное кодирование устраняет избыточность, приводит к сокращению длины сообщений, а значит, позволяет уменьшить время передачи или объем памяти, необходимой для их хранения.
Рассмотрим код Хаффмана и алгоритм Шеннона-Фано .
Код Хаффмана — статистический способ сжатия, который дает снижение средней длины кода используемого для представления символов фиксированного алфавита. Код Хаффмана является примером кода, оптимального в случае, когда все вероятности появления символов в сообщении — целые отрицательные степени двойки. Код Хаффмана может быть построен по следующему алгоритму:
1. Выписываем в ряд все символы алфавита в порядке возрастания или убывания вероятности их появления в тексте;
2. Последовательно объединяем два символа с наименьшими вероятностями появления в новый составной символ, вероятность появления которого полагается равной сумме вероятностей составляющих его символов; в конце концов, мы построим дерево, каждый узел которого имеет суммарную вероятность всех узлов, находящихся ниже него;
3. Прослеживаем путь к каждому листу дерева помечая направление к каждому узлу (например, направо — 1, налево — 0).
Для заданного распределения частот символов может существовать несколько возможных кодов Хаффмана, — это дает возможность определить каноническое дерево Хаффмана, соответствующее наиболее компактному представлению исходного текста.
Близким по технике построения к коду Хаффмана являются коды Шеннона-Фано, предложенные Шенноном и Фано в 1948-49 гг. независимо друг от друга. Их построение может быть осуществлено следующим образом:
1. Выписываем в ряд все символы в порядке возрастания вероятности появления их в тексте;
2. Последовательно делим множество символов на два подмножества так, чтобы сумма вероятностей появления символов одного подмножества была примерно равна сумме вероятностей появления символов другого. Для левого подмножества каждому символу приписываем » 0″, для правого — » 1″. Дальнейшие разбиения повторяются до тех пор, пока все подмножества не будут состоять из одного элемента.
Алгоритм создания кода Хаффмана называется » снизу-вверх», а Шеннона-Фано — » сверху-вниз». Преимуществами данных методов являются их очевидная простота реализации и, как следствие этого, высокая скорость кодирования/декодирования. Основным недостатком — неоптимальность в общем случае.
Для обеспечения высокой достоверности передачи информации по каналу с помехами применяют помехоустойчивое кодирование. Помехоустойчивые коды должны обеспечивать как обнаружение, так и исправление ошибок (корректирующие коды), т.е. кодирование должно осуществляться так, чтобы сигнал, соответствующий последовательности символов, после воздействия на него предполагаемой в канале помехи оставался ближе к сигналу, соответствующему конкретной переданной последовательности символов, чем к сигналам, соответствующим другим возможным последовательностям. Степень близости обычно определяется по числу разрядов, в которых последовательности отличаются друг от друга. Это достигается ценой введения при кодировании избыточности (избыточных, дополнительных символов), которая позволяет так выбрать передаваемые последовательности символов, чтобы они удовлетворяли дополнительным условиям, проверка которых на приемной стороне дает возможность обнаружить и исправить ошибки. Все помехоустойчивые коды можно разделить на два типа:
— обнаруживающие (проверочные EDC – Error Detection Code);
— корректирующие (ECC – Error Correction Code).
У подавляющего большинства существующих в настоящее время помехоустойчивых кодов избыточность является следствием их алгебраической структуры. В связи с этим их называют алгебраическими кодами. Алгебраические коды можно подразделить на два больших класса: блоковые и непрерывные. В случае блоковых кодов процедура кодирования заключается в сопоставлении каждой букве сообщения (или, что чаще, последовательности из k двоичных символов, соответствующих этой букве) блока из n двоичных символов. Блоковый код называют равномерным, если n остается постоянным для всех букв сообщения. Отношение k/n определяют как относительную скорость кода.
Различают разделимые и неразделимые блоковые коды. При кодировании разделимыми кодами выходные последовательности состоят из символов, роль которых может быть четко разграничена. Это, во-первых, k информационных символов, совпадающих с символами последовательности, поступающей на вход кодера, во-вторых, (n-k) избыточных (проверочных) символов, вводимых в исходную последовательность кодером, и служащих для обнаружения и исправления ошибок. При кодировании неразделимыми кодами разделить символы выходной последовательности на информационные и проверочные невозможно. Непрерывными (древовидными) называют такие коды, в которых введение избыточных символов в кодируемую последовательность информационных символов осуществляется непрерывно, без разделения ее на независимые блоки.
Использование избыточности для обнаружения ошибок
Пусть на вход кодера поступает последовательность из k информационных двоичных символов. На выходе ей соответствует последовательность из n двоичных символов, причем n> k. Всего может быть 2k различных входных и 2n различных выходных последовательностей. Из общего числа 2n выходных последовательностей только 2k последовательностей соответствуют входным. Назовем их разрешенными кодовыми комбинациями. Остальные 2n-2k возможные выходные последовательности для передачи не используются. Они могут возникнуть лишь в результате ошибки передачи. Назовем их запрещенными комбинациями. Каждая из 2k разрешенных комбинаций в результате действия помех может трансформироваться в любую другую, всего имеется 2k2n возможных случаев передачи. В это число входят:
· 2k случаев безошибочной передачи ( );
· 2k(2k-1) случаев перехода в другие разрешенные комбинации, что соответствует необнаруживаемым ошибкам ( );
· 2k(2n-2k) случаев перехода в неразрешенные комбинации, которые могут быть обнаружены ( ).
Большинство разработанных до настоящего времени кодов предназначено для корректирования взаимно-независимых ошибок определенной кратности и пачек (пакетов) ошибок. Взаимно-независимыми ошибками будем называть такие искажения в передаваемой последовательности символов, при которых вероятность появления любой комбинации искаженных символов зависит только от числа искаженных символов r и вероятности искажения одного символа p. Эти ошибки чаще всего вызываются флуктуационными помехами. Кратностью ошибки называют количество искаженных символов в кодовой комбинации. Наиболее вероятны ошибки меньшей кратности. Их и следует обнаруживать и исправлять в первую очередь.
Геометрический подход к кодированию
Методам вычисления скорости передачи информации R и пропускной способности С дискретного канала без памяти, может быть дано геометрическое толкование, которое приводит к новым результатам и новому пониманию свойств этих величин.
Пусть канал определен матрицей  вероятностей перехода от буквы i на входе к букве j на выходе
вероятностей перехода от буквы i на входе к букве j на выходе

Можно рассматривать каждую строку этой матрицы как вектор или точку в (b—1)-мерном равностороннем симплексе – 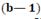 -мерный аналог отрезка прямой, равностороннего треугольника, тетраэдра и т. д. Координатами точки являются ее расстояния от граней, в сумме равные единице. Они известны под названием барицентрических координат.
-мерный аналог отрезка прямой, равностороннего треугольника, тетраэдра и т. д. Координатами точки являются ее расстояния от граней, в сумме равные единице. Они известны под названием барицентрических координат.
Таким образом, с входом i связывается точка или вектор 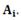 Его компоненты равны вероятностям различных букв на выходе, если используются все входы. Если использованы все входы (с вероятностью
Его компоненты равны вероятностям различных букв на выходе, если используются все входы. Если использованы все входы (с вероятностью 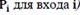 то вероятности букв на выходе даются компонентами векторной суммы.
то вероятности букв на выходе даются компонентами векторной суммы.
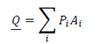
Вектору или точке Q симплекса соответствуют также вероятности букв на выходе. Тогда j-я компонента этого вектора равна
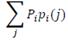
Поскольку 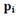 неотрицательны и в сумме дают единицу, то точки Q лежат в выпуклой оболочке (или барицентрической оболочке) точек
неотрицательны и в сумме дают единицу, то точки Q лежат в выпуклой оболочке (или барицентрической оболочке) точек 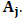 Более того, любая точка в этой выпуклой оболочке может быть получена при подходящем выборе
Более того, любая точка в этой выпуклой оболочке может быть получена при подходящем выборе 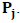
Теперь для удобства обозначений определим энтропию точки или вектора из симплекса как энтропию барицентрических координат точки, интерпретированных как вероятности. Таким образом, имеем
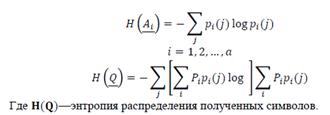
В этих обозначениях скорость передачи R для данной системы вероятностей на входе 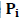 задается формулой
задается формулой
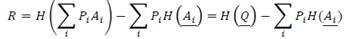
Функция 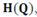 где Q — точка симплекса, является выпуклой кверху функцией. Так, если компоненты Q равны
где Q — точка симплекса, является выпуклой кверху функцией. Так, если компоненты Q равны 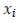 то имеем:
то имеем:
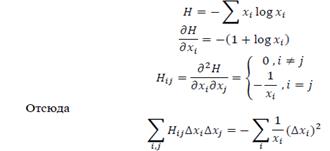
является отрицательно определенной формой. Это справедливо для пространства всех неотрицательных  и отсюда, конечно, и для подпространства, в котором
и отсюда, конечно, и для подпространства, в котором 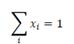
Следовательно, скорость R, о которой шла речь выше, всегда неотрицательна. Н строго выпукла (без плоских участков), и R положительна, если только 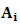 не равно Q для всех тех i, для которых
не равно Q для всех тех i, для которых 
Процесс вычисления R может быть легко изображен наглядно в случае двух или трех букв на выходе. Если на выходе имеется три буквы, то представим себе равносторонний треугольник на некоторой основной плоскости. Это будет симплекс, содержащий точки 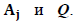 Сверху этот треугольник покрыт куполообразной поверхностью, как показано на рис. 1.
Сверху этот треугольник покрыт куполообразной поверхностью, как показано на рис. 1.
Главные характеристики качественного кода

Сложно дать точное определение чистому коду, и, скорее всего, сколько программистов — столько определений. Однако, некоторые принципы достаточно универсальны. Я собрал девять самых релевантных и описал ниже.
Плохой код делает слишком много, чистый код сфокусирован
Каждый класс, метод и любая другая сущность должна оставаться неискаженной. Она должна следовать принципу единственной обязанности. Вкратце, можно сказать так: если подумать о причинах изменения класса, то нельзя придумать больше одной хорошей причины.
Но я бы не ограничивал определение классами. В свой последней статье Ральф Вестфал (Ralf Westphal) представил более широкое определение принципа единственной обязанности:
Функциональная единица на определенном уровне абстракции должна отвечать за один аспект требований системы. Аспект требований это признак или свойство требования, которое может изменяться независимо от других аспектов.
Язык, на котором вы написали код, должен выглядеть как будто его создали для решения этой проблемы.
Не язык делает программу простой, а программист, который делает так, что язык выглядит просто.
(цитата Роберта C. Мартина)
Это означает, что не нужно использовать хаки, из-за которых код и язык обычно выглядят неуклюже. Если вы считаете, что что-то можно сделать только хаком или заплаткой, то обычно это значит, что вы недостаточно времени провели в попытках найти хорошее, чистое решение.
Не нужно избыточности
Код должен подчиняться правилу DRY (Don’t repeat yourself — не повторяйся). Если это так, то модификация любого элемента системы не требует изменения других, логически не связанных элементов.
Читать ваш код должно быть приятно
Когда читаешь ваш код, должно быть ощущение, что читаешь «Гарри Поттера» (да, знаю, я немного переборщил). Должно быть ощущение, что его написали, чтобы любой разработчик мог с легкостью прочитать, не проводя часы в попытках разобраться.
Для этого нужно стараться подчиняться принципам KISS (Keep It Simple, Stupid!) и YAGNI (You Ain’t Gonna Need It — Вам это не понадобится). Принцип KISS гласит, что большинство систем работают лучше всего если сохранять их простоту, а не развивать сложность.
То есть, простота должна быть целью в дизайне, и нужно избегать ненужных усложнений. YAGNI это практика, мотивирующая фокусироваться на простейших вещах, которые позволяют вашему софту работать.
Другой разработчик может легко расширить ваш код
Вы не пишите код для себя, или еще хуже — для компилятора. Вы пишите код для других разработчиков. Не будьте эгоистом — подумайте о людях. Не пытайте других разработчиков, выдавая плохо поддерживаемый и плохо расширяемый код. К тому же, через несколько месяцев этим другим разработчиком можете оказаться вы сами.
Нужно минимизировать зависимости
Чем больше зависимостей, тем сложнее поддерживать и изменять код в будущем. Всегда (в случае с .NET, — прим. пер.) можно помочь себе минимизировать зависимости с NDEPEND, например. Он проверяет потенциальные ошибки в зависимостях в коде.
Меньше — лучше
Код должен быть минимальным. Классы и модули должны быть короткими, в идеале — всего несколько строк кода. Код должен быть хорошо разделен (в том числе внутри класса). Чем лучше вы делите код, тем легче его читать. Этот принцип хорошо влияет на пункт 4 — другим программистам будет проще понять его.
Необходимы юнит- и приемочные тесты
Код должен быть выразительным
Так что же такое чистый код?
В целом, одно последнее качестве можно назвать итогом всего вышесказанного:
Чистый код написан тем, кому не плевать.
цитата Майкла Фетерса (Michael Feathers).
Он написан тем, кто относится к коду как к искусству, и кто обращает внимание на все детали.
Тема чистого кода — очень сложна, и выходит за рамки описанного в этой статье. Так что, если вы считаете, что существуют другие характеристики чистого кода, то, пожалуйста, поделитесь ими в комментариях.
Математические аспекты хорошего кода
Введение
Программисты постоянно стараются сделать код лучше, используя для этого различные практики. Однако само понятие хорошего кода крайне расплывчато, о чём свидетельствует одно только количество книг, посвящённых этой теме, а также их объём. Например, книга «Чистый код» Р. Мартина содержит почти 500 страниц. Неужели нет возможности выразить хотя бы основные критерии хорошего кода короче?
Чтобы обнаружить такие критерии, нужно обратить внимание на тот факт, что программирование есть отражение мышления. Целесообразно поискать критерии хорошего кода в модели, которая описывает ключевые моменты этого явления.
Основными функциями мышления являются рассуждение и балансировка.
Под рассуждением понимаются действия, связанные со структурами, а именно синтез (конструирование) и анализ (декомпозиция). Под балансировкой понимается нахождение оптимального решения между двумя крайними случаями.
Кроме того, для мышления необходимы память и время. Любая модель мышления (модель вычислений) обязана включать эти два понятия. Действительно, в машине Тьюринга роль памяти играет лента, а роль времени – головка. Аналогично, в современном компьютере эти две роли выполняют RAM и CPU, соответственно.
Итак, в нашем распоряжении три аспекта, относящиеся к мышлению: рассуждение, балансировка и природа памяти/времени. Эти аспекты напрямую относятся к самой сути программирования. Каждый из этих аспектов несёт в себе математику, которая и будет использоваться для вывода критериев хорошего кода.
Качество
Программы, как и знания вообще, могут быть весьма и весьма разнообразными. Единственное, что можно сказать с уверенностью о любой программе (или любом абстрактном объекте вообще), это наличие структуры.
Любой программе или абстрактному объекту можно поставить в соответствие дерево, где корень – сама программа, а дочерние вершинами являются её элементы, далее элементы элементов, и т.д. (рекурсивный процесс).
Каким способом можно измерить подобное дерево? В наличии два способа.
Первый, можно пересчитать количество дочерних вершин в дереве, или другими словами, рекурсивно посчитать количество поддеревьев. Число таких всех поддеревьев будем называть объёмом и обозначать как  .
.
Несколько более осмысленным измерением будет рекурсивный подсчёт только уникальных поддеревьев, их число будем называть сложностью и обозначать как  .
.
С точки зрения количества знаний, заключённых в программе, имеет значение именно сложность, т.к. повторение сказанного (написанного) не создаёт новые знания. С другой стороны, поскольку как память, так и время конечны, мы заинтересованы в минимизации объёма программы.
С учётом вышесказанного, можно определить качество  программы
программы  как отношение её сложности к объёму:
как отношение её сложности к объёму:

Таким образом, хороший код (очевидно!) должен обладать более высоким качеством, просто исходя из соображения конечности ресурсов. Вместе с тем, как показано ниже, требование качества не является абсолютным и не должно трактоваться как таковое.
Гармония
Рассмотрим, как выглядит оптимальная программа, отталкиваясь от того, как работает аппарат балансировки в принципе (это одна из важнейших функций мышления). При рассмотрении более конкретных программ могут появляться более сложные критерии оптимальности, но есть ли понятие оптимальной программы как таковой?
Оптимизация (гармония) есть поиск сбалансированного решения между двумя крайними случаями. Проблема заключается в том, что математика балансировки описана только для чисел (золотое сечение). Однако, отсутствие описания НЕ эквивалентно его отсутствию. В действительности, если исходить из того, что аппарат балансировки един как для чисел, так и для структур вообще, то математику балансировки программ получить не трудно.
Уравнение балансировки чисел выглядит так:

Из этого уравнения выводится значение золотого сечения  .
.
Теперь представим, что  и
и  – это компоненты программы. Мы не можем напрямую применить данное уравнение к программам, т.к. их нельзя умножать друг на друга, а также складывать и вычитать. Тем не менее, мы можем провести преобразования, которые сохранят смысл уравнения и сделают его пригодным для обобщённых структур и в частности, программ.
– это компоненты программы. Мы не можем напрямую применить данное уравнение к программам, т.к. их нельзя умножать друг на друга, а также складывать и вычитать. Тем не менее, мы можем провести преобразования, которые сохранят смысл уравнения и сделают его пригодным для обобщённых структур и в частности, программ.
Если опустить длинное математическое обоснование, то для программ (и абстрактных объектов вообще) уравнение балансировки приобретает вид:

Здесь  и
и  – это функции сходства и различия. Данные понятия являются неотъемлемой частью модели мышления. Действительно, о каких бы двух объектах ни шла речь, мы всегда можем указать (спросить), что между ними общего и в чём они различаются.
– это функции сходства и различия. Данные понятия являются неотъемлемой частью модели мышления. Действительно, о каких бы двух объектах ни шла речь, мы всегда можем указать (спросить), что между ними общего и в чём они различаются.
Функции сходства и различия заменяют в уравнении балансировки сложение и вычитание, соответственно. А использование сложности позволяет обращаться с программой как с числом, как в исходном уравнении.
В словесной форме, уравнение является требованием того, чтобы взаимная сложность объектов была уравновешена взаимной сложностью их сходства и различия.
Это уравнение говорит о том, что программа является оптимальной тогда, когда между компонентами программы поровну сходства и различия. Из этого правила могут быть исключения, например справочник, который содержит строго различные элементы. Для остальных программ (в общем случае) оптимальность описывается именно через уравнение балансировки.
Левую часть уравнения обозначим как  – значение гармонии
– значение гармонии  и
и  (для большего количества элементов гармония считается по всем парам). Хотя точный подсчёт
(для большего количества элементов гармония считается по всем парам). Хотя точный подсчёт  для кода на высокоуровневом языка пока затруднителен, похожесть и непохожесть (например, избыток похожих компонентов) глаз программиста распознаёт быстро и безошибочно, «на уровне BIOS’а».
для кода на высокоуровневом языка пока затруднителен, похожесть и непохожесть (например, избыток похожих компонентов) глаз программиста распознаёт быстро и безошибочно, «на уровне BIOS’а».
Таким образом, оптимальный код должен иметь значение  ближе к единице.
ближе к единице.
Целостность
Для программы крайне важна предсказуемость. Под этим понимается точное следование некоторому контракту, что в свою очередь, связано с понятием времени. При нарушении контракта возникает противоречие, которое представлено как исключение в языках программирования. В то время как исключения суть обычный инструмент разработки, неожиданное исключение это явное зло.
Если код точно следует контракту, будем называть его строгим. От написанных таким образом компонентов обычно не ожидается внезапное исключение, например Dictionary. Проблема в том, что контракт не всегда полностью осознаётся, или не до конца проработан.
Приведём пример. Следующий код (на языке C#) отражает поведение абстрактного (математического) времени. Чтение, изменение, запись – это основные функции времени, которые образуют любую модель вычислений.
public sealed class marker {
public dynamic argument;
void move(dynamic previous, dynamic next) {
argument = previous?.read();
argument = transform(argument);
next?.write(argument); }}На первый взгляд, с этим кодом всё в порядке. Однако задумаемся вот о чём. Входное множество (dynamic previous, dynamic next) состоит из двух элементов. Если мы передадим в функцию move один и тот же объект, по факту это приведёт к тому, что множество будет состоять из одного элемента (одинаковые элементы в множествах не допускаются). Контракт, который заключается в неизменности объекта previous, будет нарушен.
Подобное нарушение контракта распознаётся в математике как противоречие, а в программировании как исключение, поэтому (в общем случае) необходима дополнительная строчка:
argument = previous?.read();
argument = transform(argument);
if(previous?.Equals(next)) throw new Exception();
next?.write(argument); }}В более общем смысле, можно показать, что противоречие возникает в случае, когда уничтожается или игнорируется какой-либо способ отличить одно от другого. В указанном примере, когда previous равен next, утрачивается способ отличить предыдущий объект от следующего.
Если код написан с учётом этого аспекта, т.е. не допускает потерю знаний, это эквивалентно его строгости. Понятно, что поведение строгого кода более предсказуемо, нежели не строгого. Долю строгого кода в приложении будем называть целостностью и обозначать  .
.
Интегральная характеристика
Мы показали, что исходя из аспектов программирования – рассуждения и балансировки, а также из необходимости сохранения знаний и следования контракту, предпочтительными для кода являются:
бо́льшее качество
 ;
;лучшая гармония, т.е. меньшее расстояние между
 и единицей;
и единицей;
Объединим, для программы  , эти условия в интегральную характеристику
, эти условия в интегральную характеристику  :
:

Таким образом, хорошая программа будет отличаться более высоким значением характеристики  . На практике подсчитать эту величину для программы на языке высокого уровня пока затруднительно. Тем не менее, программист достаточно легко оценивает качество и гармонию (сбалансированность) программы, просто глядя на код. Что касается целостности, она также может быть оценена при анализе кода.
. На практике подсчитать эту величину для программы на языке высокого уровня пока затруднительно. Тем не менее, программист достаточно легко оценивает качество и гармонию (сбалансированность) программы, просто глядя на код. Что касается целостности, она также может быть оценена при анализе кода.
Надо указать, что сложность программы естественным образом должна быть ограничена сложностью решаемой задачи. Повышение качества должно достигаться за счёт снижения объёма, а не увеличения сложности, в противном случае слепое следование формуле  может привести к негативным результатам.
может привести к негативным результатам.
Например, если в программе нужно сложить два числа, то можно искусственно увеличить сложность, написав целый калькулятор и применив его для сложения. Результирующий код даже может обладать лучшим значением  , что противоречит здравому смыслу.
, что противоречит здравому смыслу.
Введём понятие полной сложности решаемой задачи  . Понятно, что если задача решена целиком, то сложность программы не может быть меньше полной сложности:
. Понятно, что если задача решена целиком, то сложность программы не может быть меньше полной сложности:  . Однако дальнейший рост сложности не оправдан, поэтому формулу
. Однако дальнейший рост сложности не оправдан, поэтому формулу  необходимо переписать:
необходимо переписать:

В словесной форме, формула говорит, что хороший код должен быть лаконичным, сбалансированным и должен сохранять знания. Указанные аспекты (качество, гармония, целостность) хорошего кода естественным образом вытекают из того, что мы знаем о нашем мышлении.
Отметим, что значения  ,
,  ,
,  и
и  не являются изолированными. Улучшение одного параметра может иметь (и, как правило, имеет) цену ухудшения другого. По этой причине, элементы формулы не должны применяться поодиночке.
не являются изолированными. Улучшение одного параметра может иметь (и, как правило, имеет) цену ухудшения другого. По этой причине, элементы формулы не должны применяться поодиночке.
Таким образом, хорошим должен считаться код, который максимизирует значение интегрального критерия, даже несмотря на то, что значения объёма, гармонии и целостности (возможно) не достигают своих максимальных значений по отдельности. Можно показать, что следование принципам проектирования приводит (в общем случае) к максимизации интегрального критерия  .
.
Размеры
Укажем, что мышление человека не очень-то хорошо управляется с цепочками большой длины. Так, человек способен (примерные данные) за один миг воспринять (запомнить) два предмета и их порядок, или три предмета без запоминания порядка, или количество предметов до пяти. При удлинении цепочек время восприятия возрастает экспоненциально.
Аналогично, разум человека значительно хуже воспринимает длинный код, а также код с большим количеством длинных строчек («простыня»). По опыту, можно указать, что оптимальная длина класса – до 250 строк, метода – до 30-40 строк, списка параметров – до трёх, в редких случаях до 5 параметров. Излишне длинный код также говорит о том, что он недостаточно насыщен структурой.
В то же время, возможны случаи, когда код можно перенасытить структурой, отчего он столь же плохо читается. В данном случае налицо проблема балансировки между двумя крайними случаями, и оптимальная программа придерживается некоторого более умеренного значения: качество, но не во вред общему делу.
Заключение
То, что качество, сбалансированность и предсказуемость – черты хорошего кода, не является новостью. Целью статьи является, при помощи математики, превращение данного знания из эмпирического в строгое и теоретически обоснованное.
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение — процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики — базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом — не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня — табличка с надписью, знак на дороге, светофоры, и для современного мира — штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
1 Речь, мимика, жесты
Удивительно, но всё это — коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях. Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода — улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости.
Следуя определению, что же происходит когда мы говорим? Мысль — как форма, удобная для непосредственного использования, преобразуется в речь — форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда — человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
2 Чередующиеся сигналы

В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы «включено/выключено». Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме «точка-тире», что нам даёт букву «A» может звучать и так — «точка-пауза-тире» и тогда это уже две буквы «ET».

3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной — звук, видео, текст. Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук — череда дискретных значений о звуковом сигнале, видео — череда кадров изображений, текст — череда символов текста. Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим — час или даже пара недель.
Кодирование текста
От общего описания кодирования перейдём к практической части. Из условностей мы за константу примем то, что будем кодировать данные для персонального компьютера, где за единицу информации приняты — бит и байт. Бит, как атом информации, а байт — как условный блок размером в 8 бит.
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза «ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП».

1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
Всего нами использовано 19 символов (включая пробел). Для хранения в памяти ПК будет затрачено 18+12+11+11+9+8+4+3+2+2+2+2+1+1+1+1+1+1+1=91 байт (91*8=728 бит).
Эти значения мы берём как константы и пробуем изменить подход к хранению блоков. Для этого мы замечаем, что из 256 кодов для символов мы используем только 19. Чтобы узнать — сколько нужно бит для хранения 19 значений мы должны посчитать LOG2(19)=4.25, так как дробное значение бита мы использовать не можем, то мы должны округлить до 5, что нам даёт максимально 32 разных значения (если бы мы захотели использовать 4 бита, то это дало бы лишь 16 значений и мы не смогли бы закодировать всю строку).
Нетрудно посчитать, что у нас получится 91*5=455 бит, то есть зная контекст и изменив способ хранения мы смогли уменьшить использование памяти ПК на 37.5%.
К сожалению такое представление информации не позволит его однозначно декодировать без хранения информации о символах и новых кодах, а добавление нового словаря увеличит размер данных. Поэтому подобные способы кодирования проявляют себя на бОльших объемах данных.
Кроме того, для хранения 19 значений мы использовали количество бит как для 32 значений, это снижает эффективность кодирования.